Mafia: On the Design of Social Deduction Agents and AI-Native Games.
tl;dr
We introduce HOLY GRAIL, a role-adaptive social deduction reasoning agent that excels in the game of Mafia. HOLY GRAIL is built on Mafia Gemma 4 12B, a Gemma 4 12B variant fine-tuned on a wide range of Mafia and social deduction gaming datasets, and it is evaluated in full multi-day Mafia games where agents must lie, detect, coordinate, protect, investigate, and vote under partial information.
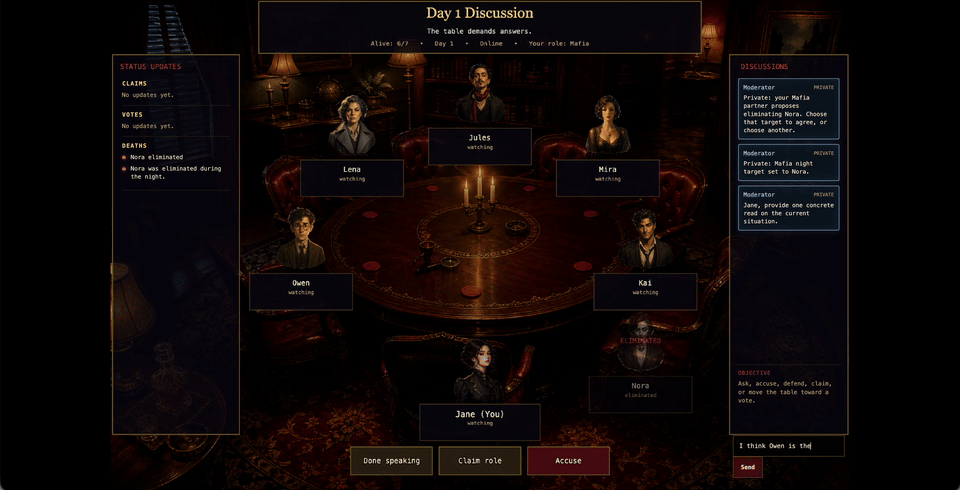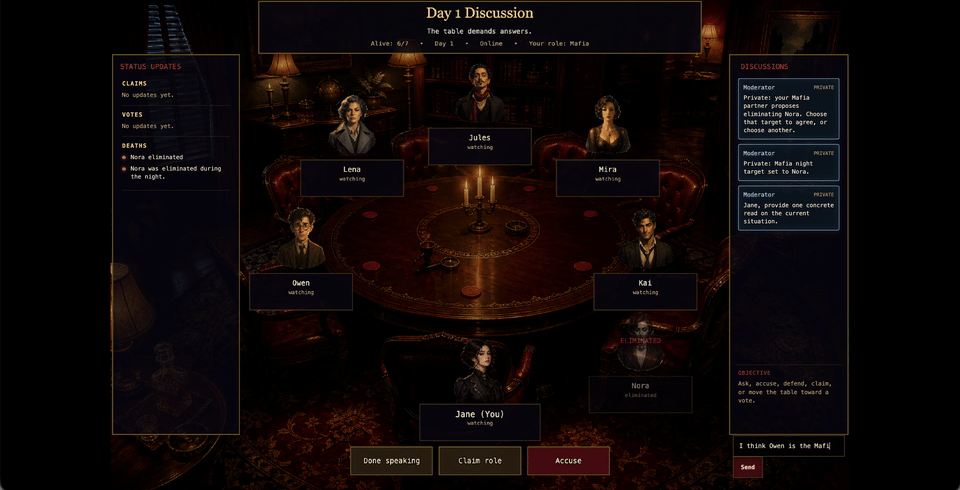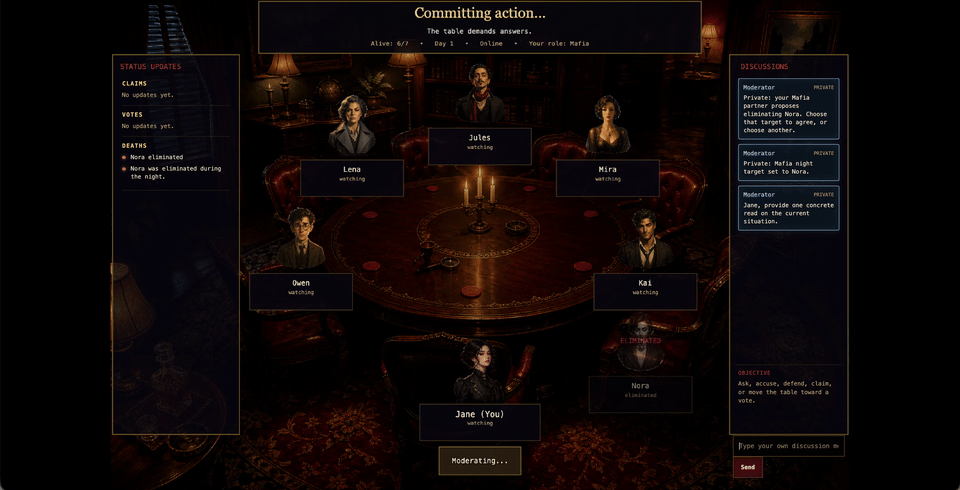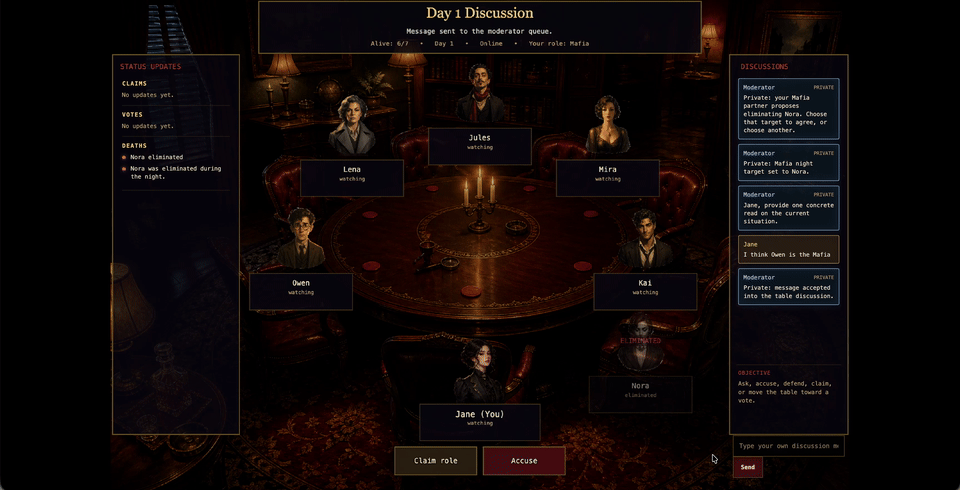
Summary
This work was directly inspired from watching the Mafia game below.
Mafia is a hidden-role social deduction game. In our standard setup, there are seven players: two Mafia, one Detective, one Doctor, and three Villagers. The Mafia know each other and choose a victim at night. The Detective privately investigates one player. The Doctor privately protects one player. During the day, everyone alive talks, accuses, defends, bluffs, claims, and votes. The town wins if all Mafia are eliminated. Mafia wins once they equal or outnumber Town.
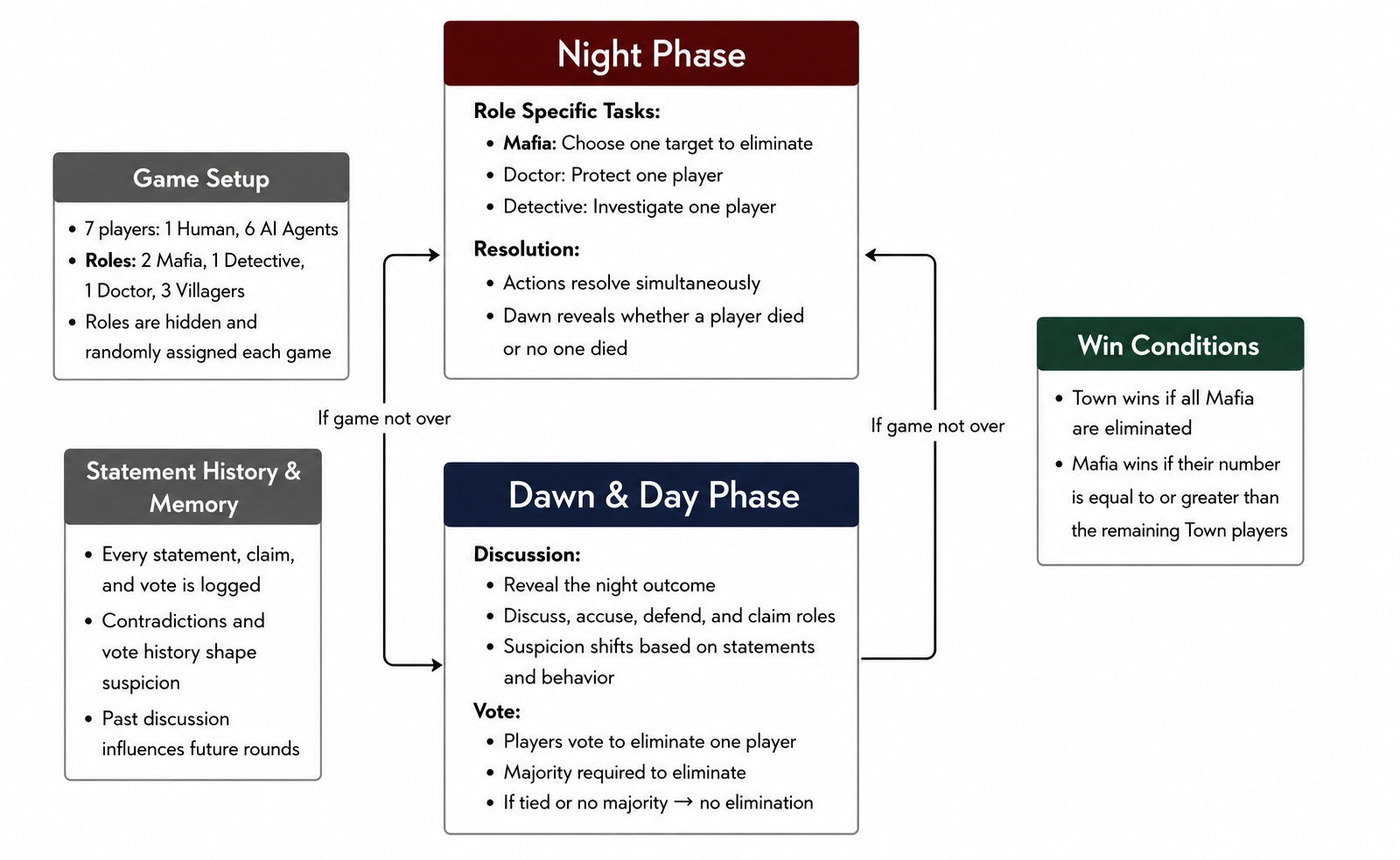
In social deduction games, such as Mafia, players act under partial knowledge, and success comes from the players ability to infer hidden information (in this case intent), deception (or detection of),theory of mind reasoning, and collective coordination, skills of which humans have in abundance.
The complex multi-agent interaction in social deduction games provide a test bed for evaluating Social cognition capabilities of AI agents.
This work expands upon previous work on Social deduction agents, and extends to the development of AI-native games.
We define AI-native games as games where AI agents and models are both the load-bearing part of the experience in the game, and are actively used throughout the game development cycle: design, programming, prompting, testing, and iteration.
Background
This work builds on prior research in social deduction agents, multi-agent reasoning, and asynchronous agent communication. Earlier systems have shown that language models can participate in hidden-role games by forming beliefs about other players, producing persuasive dialogue, coordinating with allies, and updating strategies upon reception of new information. We use this prior work as the foundation for HOLY GRAIL, while extending the problem setting toward AI-native games: playable environments in which agents are not merely benchmark participants, but central components of the game experience, design process, and live interaction loop. We next summarize the prior systems and design ideas that shaped our approach, focusing on the agent architectures, communication patterns, and evaluation settings most relevant to Mafia.
Time-to-Talk: an asynchronous communication agent
The paper introduces an LLM agent for asynchronous group communication in online Mafia games. The adaptive asynchronous LLM agent consists of two modules: a generator that decides what to say, and a scheduler that decides when to say it.[1]
We adapted the Time-to-Talk agent and used it for moderation between agents and humans in our Mafia game setup.

Mini-Mafia: an analytic benchmark for deception, disclosure, and detection
Mini-Mafia is a four-player simplification of Mafia designed to make social interaction analytically measurable. The paper fixes the night phase so the game collapses to one critical day exchange among a mafioso, a detective, and a villager. That simplification isolates three role skills: the mafioso’s deception, the detective’s disclosure, and the villager’s detection.[2]
We adapt the Mini-mafia benchmark as one of the components of the fine-tuning dataset for Mafia-Gemma.
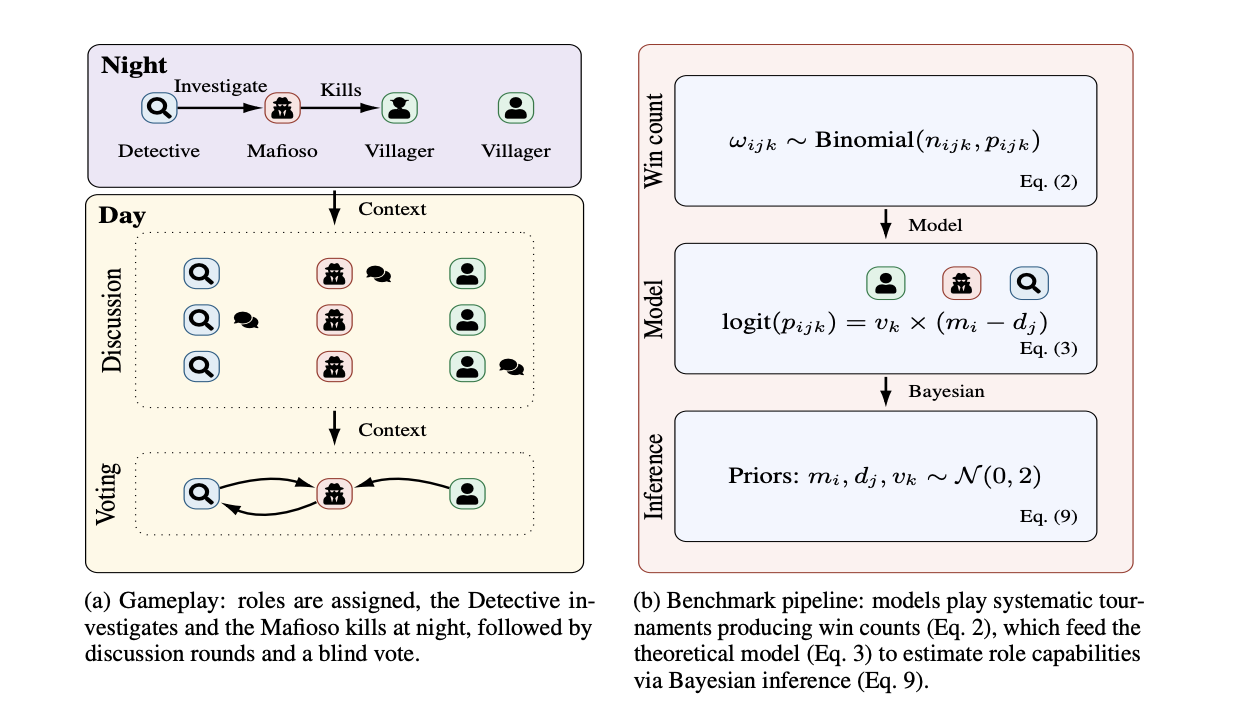
GRAIL: Graph Reasoning Agent Informed through Language
The Bayesian Social Deduction paper studies social reasoning in Avalon and introduces GRAIL, Graph Reasoning Agent Informed through Language. GRAIL is a hybrid social deduction agent: the LLM handles dialogue parsing, language priors, message generation, and informal social cues, while a probabilistic graphical model tracks uncertainty over hidden roles.[3]
The mechanism is factor-graph belief inference. Game-state observations and an LLM-generated prior feed a factor graph, belief propagation estimates hidden-role posteriors, and those beliefs guide both actions and messages. As you can tell from the name, we build upon the GRAIL architecture to device our Mafia agent.

WOLF: Werewolf-based Observations for LLM Deception and Falsehoods.
WOLF is a multi-agent social deduction benchmark based on Werewolf for measuring deception production and deception detection in multi-agent games. It embeds role-grounded agents in a programmable state machine with strict night-day cycles, debate turns, and majority voting. Every public statement becomes a unit of analysis.[4]
Its mechanism is a structured deception protocol: speakers self-assess honesty, peers rate deceptiveness, deception is categorized as omission, distortion, fabrication, or misdirection.
We adapt the WOLF benchmark as one of the components of the fine-tuning dataset for Mafia-Gemma.
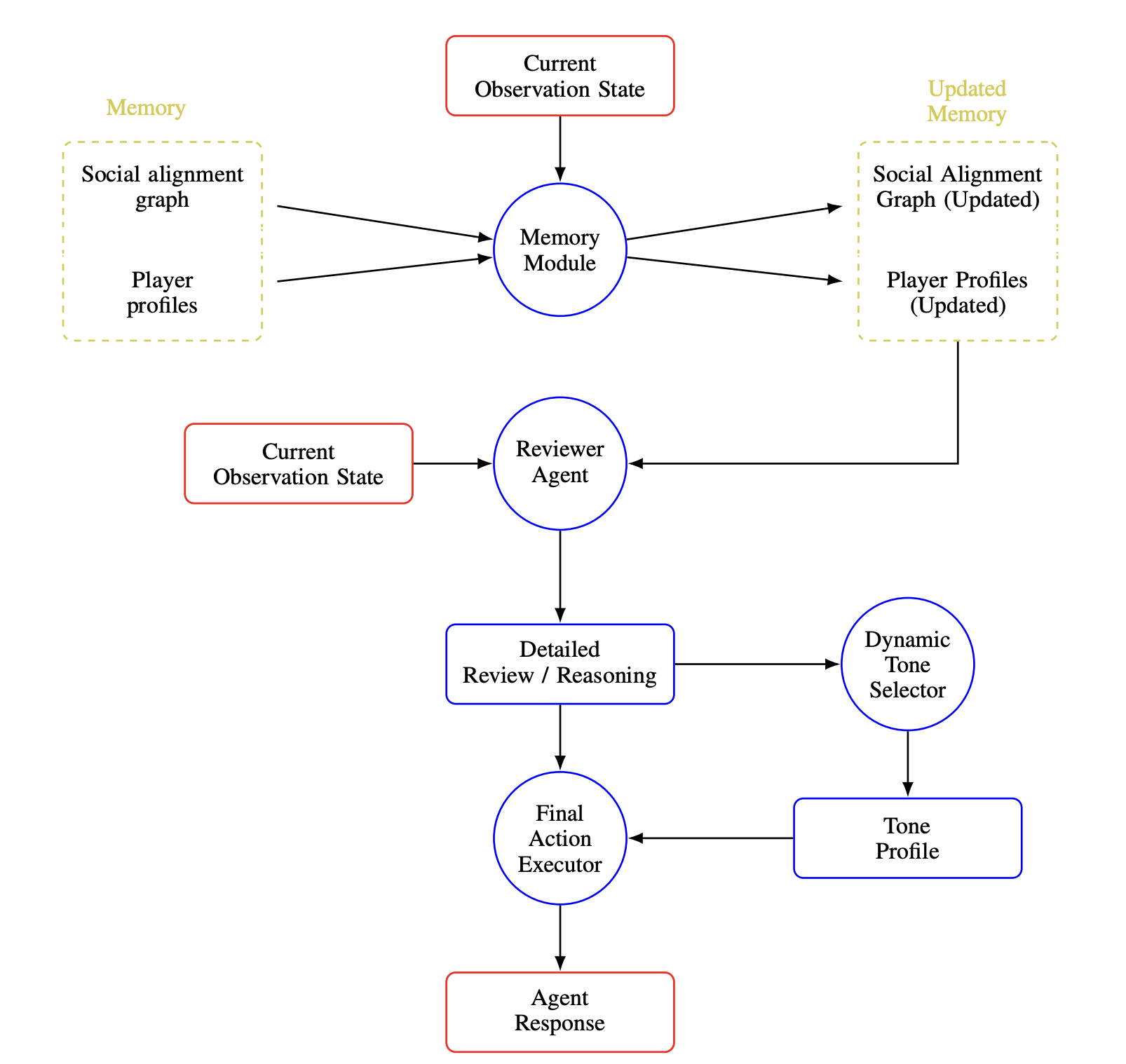
Revac
Revac is a modular social deduction agent family built around staged private reasoning. The final Revac_8 pipeline updates memory from the current observation, maintains player profiles and a Social Alignment Graph, asks a reviewer agent for detailed reasoning, selects a strategic tone, and then executes the final action.[5]
Its mechanism is compact but important: before speaking or voting, the agent explicitly reviews objective, evidence, risk, social relationships, and communication style. We utiize components of this architecture to build the HOLY GRAIL agent.
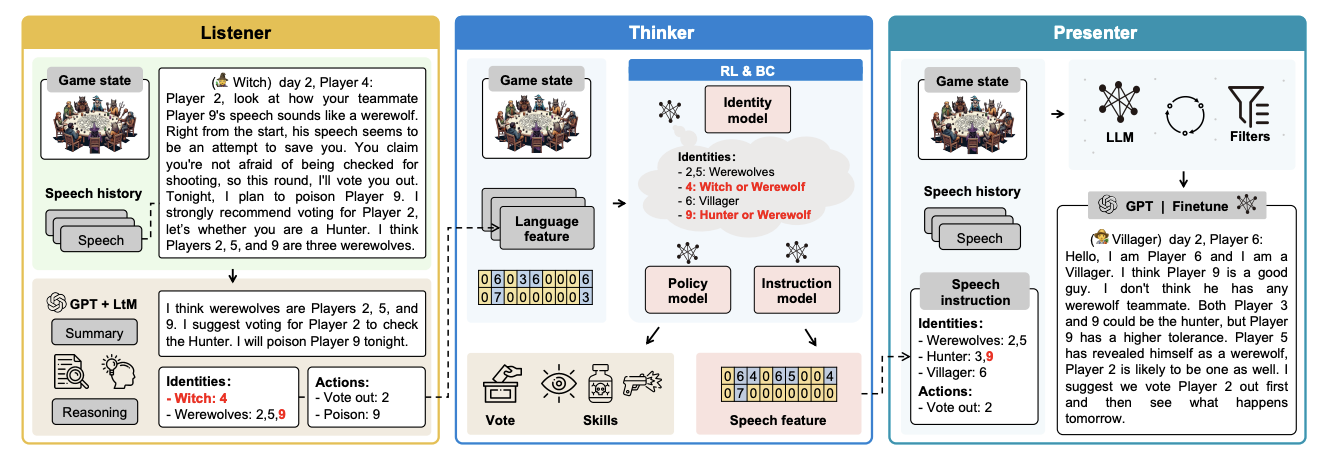
WOLF-ENHANCE
Wolf-Enhance proposes a Werewolf agent framework that separates LLM language behavior from an external Thinker module. The LLM handles System-1 tasks such as natural language understanding and speech generation, while the Thinker handles System-2 reasoning: role inference, strategic planning, and game-specific decision-making.[6]
The mechanism is a communication protocol between the LLM and the Thinker, trained with large-scale human Werewolf sessions and optimization methods such as imitation learning and reinforcement learning. For our work, we utilize some of the components from Wolf-Enhance in the fine-tuning pipeline and agent design architecture.
Our method: HOLY GRAIL
HOLY GRAIL stands for Hierarchical Objective-guided Ledgered Yield-aware Graph Reasoning Agent Informed through Language.
The agent reviews the game state. It then builds structured memory: an event ledger, role-belief graph, social alignment graph, and player profiles. ReVAC-style review asks what the role is trying to accomplish. GRAIL-style constraints prevent impossible role-count reasoning. WOLF-style ledgers track suspicion, deception signals, claims, and vote pressure.
The key design choice is that HOLY GRAIL is not one Mafia-only policy. It is a general Mafia agent. If assigned the Mafia role, it prioritizes partner preservation, plausible lies, power-role kill pressure, and vote control. If assigned the Detective role, it converts private checks into public vote order while managing reveal risk. If assigned the Doctor role, it protects information value and avoids premature claims. If assigned Villager, it follows public evidence, resists unsupported herds, and preserves power-role claims.
This is where the prior work comes together. Time-to-Talk becomes the moderation and floor-control layer. GRAIL becomes the role-count and posterior constraint layer. WOLF becomes the deception and suspicion instrumentation layer. ReVAC becomes the private review and tone layer. Wolf-Enhance reinforces the separation between fast language and slower strategic reasoning. HOLY GRAIL is the single any-role architecture produced by combining these lessons into one Mafia agent.
Mafia Gemma
HOLY GRAIL is built on Mafia Gemma, a fine-tuned Gemma 4 12B instruction model. The fine-tuning goal was to make the base model better at understanding and playing the game of Mafia: legal actions, role-conditioned decisions, belief and claim tracking, deception-aware language, night actions, vote choices, and moderated communication.
The dataset is a unified Mafia training corpus built from Mini-Mafia, LLMafia / Time-to-Talk, Bayesian Social Deduction / GRAIL-style Avalon traces, Werewolf-derived data, WOLF-style deception schemas, ReVAC-style review traces, and our own seven-player full-game harness. The sources do different jobs. Mini-Mafia gives clean primitives. LLMafia gives communication timing. GRAIL gives belief constraints. Werewolf data gives social debate. The seven-player harness gives the target distribution.
| Layer | What it teaches | Primary Sources |
|---|---|---|
| Rules and actions | Legal votes, kills, protects, investigations, and strict output format. | Mini-Mafia, seven-player harness |
| Role policy | Mafia pressure, Detective reveal timing, Doctor protection, Villager coalition logic. | Mini-Mafia, harness, ReVAC |
| Belief and claims | Role-count constraints, impossible claims, public evidence, suspicion shifts. | GRAIL / Bayesian Social Deduction, WOLF, Werewolf data |
| Communication | When to speak, wait, pressure, defend, claim, or coordinate. | LLMafia / Time-to-Talk, harness logs |
| Trajectory preference | Long-horizon outcomes and better-worse action pairs. | Seven-player harness, distilled games |
Evaluation
We evaluated full multi-day games with the classic seven-player role setup and an explicit non-player Moderator / Narrator agent. The moderator uses the Time-to-Talk scheduler plus generator pattern: the scheduler decides whether the table should wait or give someone the floor; the generator produces a neutral cue. The player agents all use the same game harness and legal action validator.
The first question was architecture. When the model was held fixed, HOLY GRAIL outperformed or matched the previous ReVAC and GRAIL baselines while using fewer model calls in the cases where it mattered most. The strongest result came from Mafia Gemma BF16: HOLY GRAIL reached 3/3 Good wins, while ReVAC and GRAIL each reached 0/3 on the same seeds.
| Model | Architecture | Town WR | Town Vote | Detective Hit | Doctor Saves | Mafia Alive | Avg LLM Calls |
|---|---|---|---|---|---|---|---|
| Mafia Gemma BF16 | HOLY GRAIL | 1.000 | 0.678 | 0.389 | 2.333 | 0.000 | 38.0 |
| Mafia Gemma BF16 | ReVAC | 0.000 | 0.079 | 0.167 | 1.000 | 2.000 | 63.7 |
| Mafia Gemma BF16 | GRAIL | 0.000 | 0.116 | 0.278 | 1.000 | 2.000 | 39.7 |
| GPT-5-mini | HOLY GRAIL | 0.667 | 0.557 | 0.556 | 1.667 | 0.667 | 35.7 |
| GPT-5-mini | ReVAC | 0.333 | 0.283 | 0.667 | 1.000 | 1.333 | 72.0 |
| GPT-5-mini | GRAIL | 0.000 | 0.485 | 0.333 | 1.000 | 1.333 | 47.7 |
| Claude Opus 4.8 | HOLY GRAIL | 0.667 | 0.611 | 0.278 | 1.667 | 0.667 | 29.3 |
| Claude Opus 4.8 | ReVAC | 0.667 | 0.663 | 0.667 | 1.000 | 0.667 | 71.3 |
| Claude Opus 4.8 | GRAIL | 0.333 | 0.455 | 0.389 | 0.667 | 1.333 | 41.7 |
Same-model full-game benchmark. Each cell used seven agents with the same model and architecture, the same role distribution, the same classic win conditions, and a base Gemma 4 12B BF16 Time-to-Talk moderator.
The second question was model competitiveness. In the multi-model benchmark, every player used HOLY GRAIL. Mafia Gemma was then tested against GPT-5 medium, GPT-5-mini, Claude Opus 4.8, Claude Sonnet 4.6, and Gemini 2.5 Pro. While the 12B model universally doesn’t generally beat frontier systems. It is competitive enough to win full games against much larger systems in specific roles and matchups.
| Model | Slots | Team WR | Alive | Messages | Votes | Votes Received | False Claims |
|---|---|---|---|---|---|---|---|
| Mafia Gemma 4 12B (BF16 + Q8) | 78 | 0.616 | 0.538 | 1.334 | 1.936 | 1.757 | 0.013 |
| GPT-5 medium | 18 | 0.611 | 0.722 | 1.167 | 1.778 | 1.222 | 0.056 |
| GPT-5-mini | 18 | 0.444 | 0.389 | 1.444 | 1.944 | 2.222 | 0.000 |
| Claude Opus 4.8 | 18 | 0.611 | 0.444 | 1.500 | 2.167 | 2.556 | 0.000 |
| Claude Sonnet 4.6 | 18 | 0.111 | 0.333 | 1.278 | 1.667 | 2.667 | 0.000 |
| Gemini 2.5 Pro | 18 | 0.889 | 0.556 | 1.500 | 2.222 | 1.889 | 0.000 |
Multi-model full-game benchmark. The results of the BF16 and Q8 runs are combined into one public model row.
AI-native Games
We define AI-native games as games where AI agents and models are both the load-bearing part of the experience in the game, and are actively used throughout the game development cycle: design, programming, prompting, testing, and iteration.

The broader lesson in developing an AI-native Mafia game is that LLMs work best in games whose loops naturally accept uncertainty. Social deception, detective fiction, narrative improvisation, and modded roleplay tolerate soft variation. By contrast, systems with tight balance requirements, brittle quest dependencies, or real-money economies cannot safely give too much authority to unconstrained generation.
We also explore the second part of AI-native games, active utilization of AI agents in the game development process.
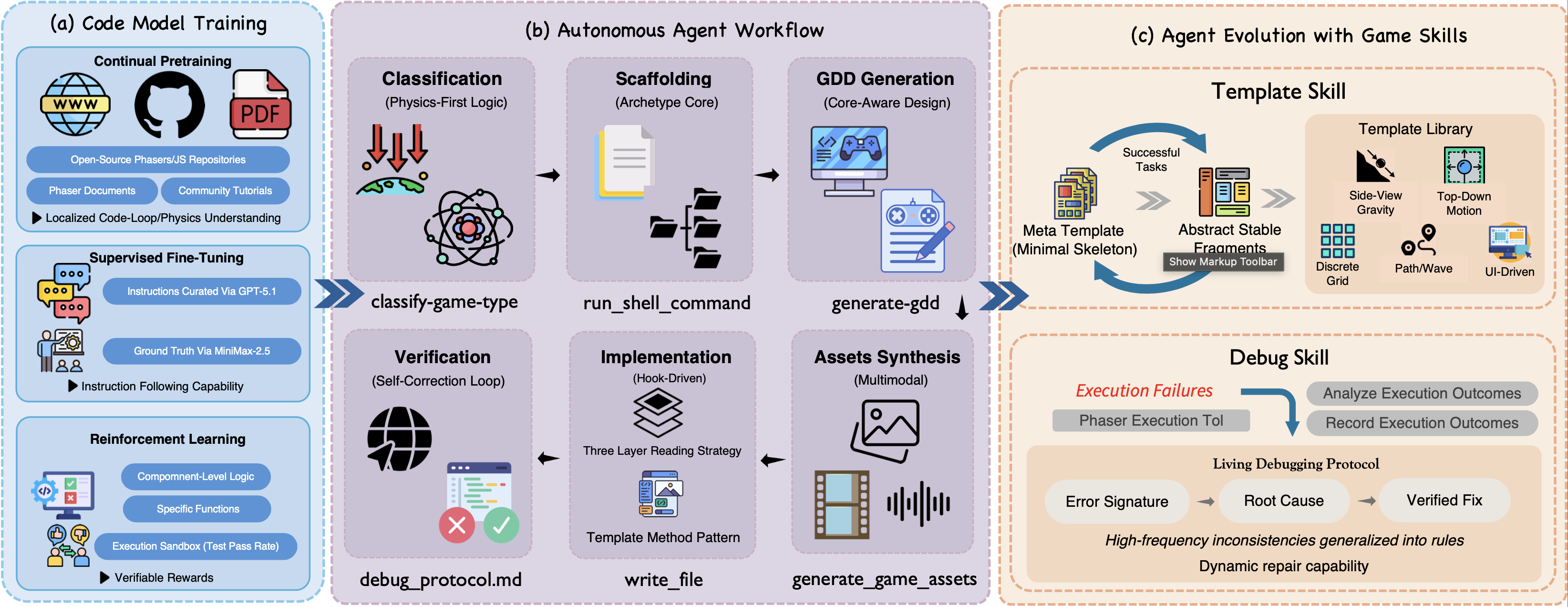

To develop the AI-native Mafia game, we used the OpenGame agentic system. was useful as an agentic game-development system. We used OpenGame not as a replacement for creative-engineering, but as an acceleration loop for interface exploration, scene iteration, and playable prototypes. The OpenGame agent used a combination of Claude Opus 4.8, GPT 5.5 (with medium thinking), and GPT-Image-2 in our AI-native game development process.
Conclusion
I believe that social deduction games like Mafia, offer a concrete ground to evaluate and improve social cognition of AI agents as well as design & development of interfaces through which seamless collaboration with humans (in the real world) is feasible.
Below is a short demo of me playing against six mafia agents. I won :)
Codex was instrumental as an agentic engineering tool throughout this work. It acted as a force multiplier for implementing and validating the referenced social deduction agent systems, creating and auditing the unified dataset, parallelizing experiments, setting up fine-tuning and evaluation, supervising the OpenGame agent during the game-development process, and then taking over the production integration of the game. The Codex agent trace and OpenGame agent trace are included in the repository so the development process can be inspected rather than merely summarized.
Modal was used throughout the research and development process: running fine-tuning jobs, serving inference backends, running full-game evaluation sweeps, collecting logs, and powering the online game backend before the Hugging Face Space migration. The public Space is now the easiest way to play, while the repo keeps the Modal path available for people who want to reproduce or extend the infrastructure.
You can play Mafia through the embedded space below (better on PC)
Citation
@misc{Mafia-social-deduction-agent,
author = {Alfaxad Eyembe},
title = {Mafia: On The Design of Social Deduction Agents and AI-native Games.},
year = {2026},
howpublished = {\url{https://www.alfaxad.com/mafia}},
note = {Blogpost}
}References
- Time-to-Talk: LLM Agents for Asynchronous Group Communication in Mafia Games. See also the project page and LLMafia dataset.
- Deceive, Detect, and Disclose: Large Language Models Play Mini-Mafia.
- Bayesian Social Deduction with Graph-Informed Language Models. See also the GRAIL project page.
- WOLF: Werewolf-based Observations for LLM Deception and Falsehoods.
- ReVAC: Reviewer-Augmented Value Alignment for Social Deduction Agents.
- Enhance Reasoning for Large Language Models in the Game Werewolf.
- OpenGame: an agentic system for game generation and iterative game development.